Ray 用例
Contents
Ray 用例#
此页索引了用于 ML 扩缩 的常见 Ray 用例。 它包含对博客、示例和教程的突出显示参考,也位于 Ray 文档中的其他位置。
LLMs 以及生成式 AI#
大型语言模型(LLM)和生成人工智能正在迅速改变行业,需求计算速度惊人。Ray 提供了一个用于扩展这些模型的分布式计算框架,使开发人员能够更快、更高效地训练和部署模型。凭借用于数据流、训练、微调、超参数调整和服务的专用库,Ray 简化了开发和部署大规模人工智能模型的过程。
批量预估#
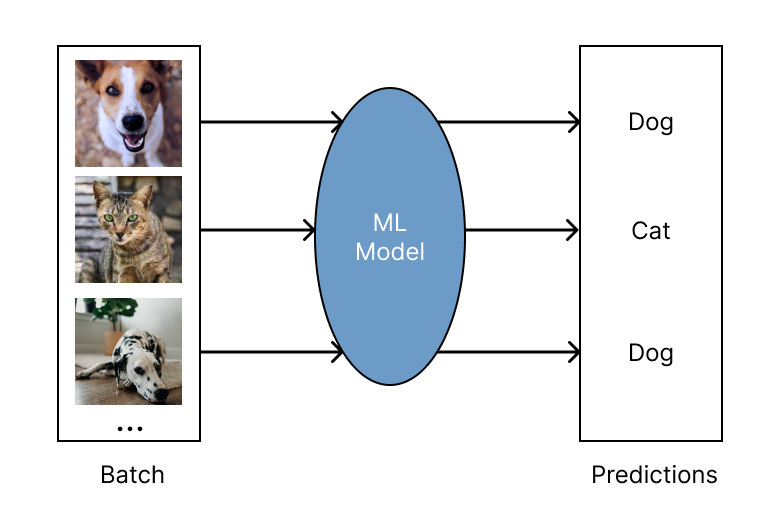
批量推理是对大量输入数据生成模型预测的过程。 Ray 针对于批量预估可工作于任何云厂商以及 ML 框架, 并且它对于现代深度学习应用程序来说既快速又便宜。 它从单机扩展到大型集群,只需最少的代码更改。 作为 Python 优先的框架,您可以在 Ray 中轻松地表达和交互式地开发推理工作负载。 了解有关使用 Ray 运行批处理推理的更多信息,参考 批量预估指导.
多模型训练#
多模型训练在 ML 用例中很常见,如时间序列预测,它需要在与地点、产品等对应的多个数据批次上拟合模型。 重点是在数据集的子集上训练许多模型。这与在整个数据集上训练单个模型形成对比。
当要训练的任何给定模型都可以放在一个 GPU 上时,Ray 可以将每个训练运行分配给一个单独的 Ray 任务。通过这种方式,所有可用的 worker 都被用来运行独立的远程训练,而不是一个工人按顺序运行作业。
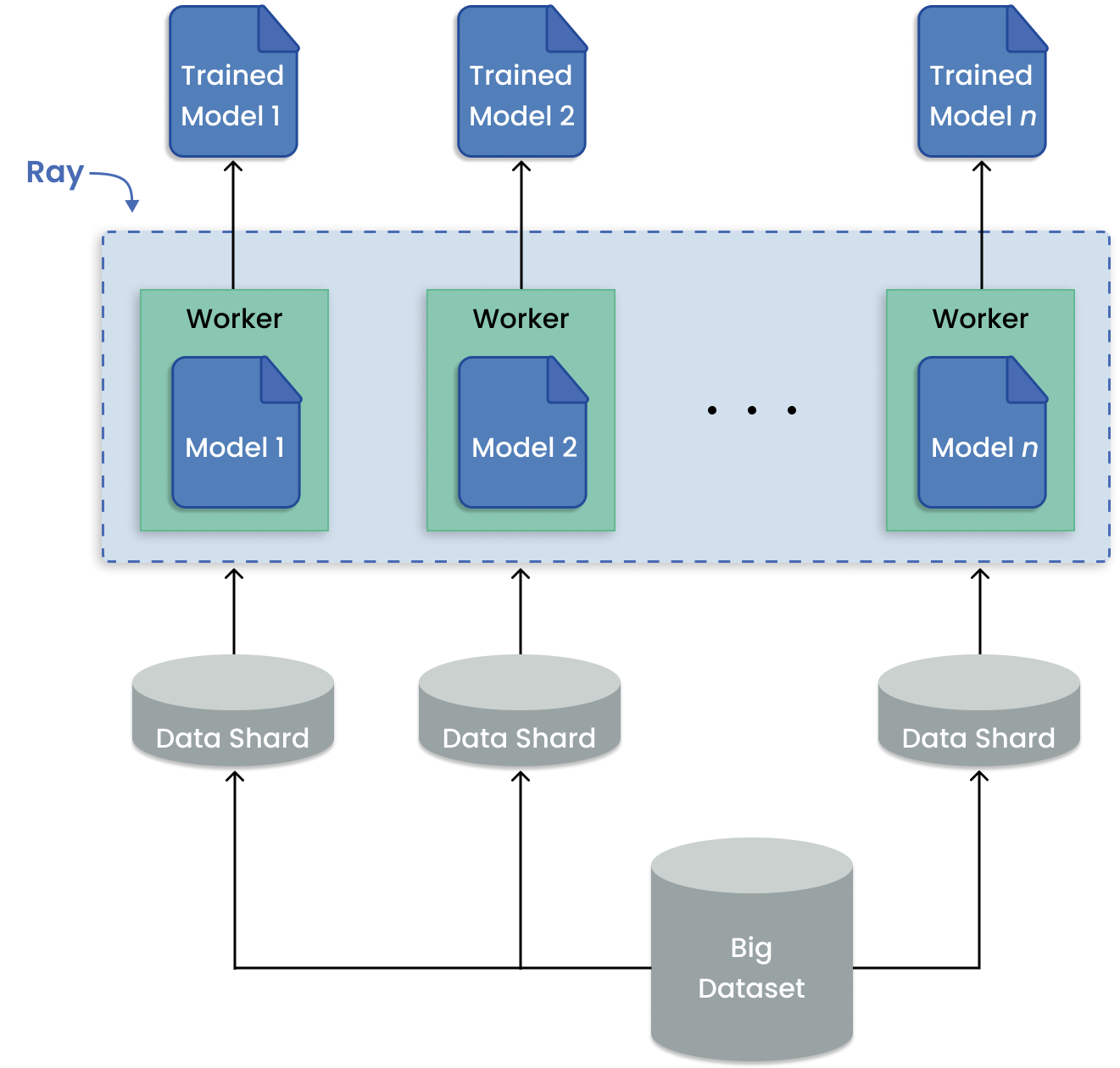
用于大型数据集上分布式训练的数据并行模式。#
我如何在 Ray 上进行多模型训练?#
要训练多个独立的模型,使用 Ray Tune (Tutorial) 类库。这是大多数情况下推荐的库。
如果数据源适合单个机器(节点)的内存,则可以将 Tune 与当前的数据预处理管道一起使用。 如果您需要扩展数据,或者希望规划未来的扩展,使用 Ray Data 类库。 要使用 Ray Data,你的数据必须是 支持的格式。
对于不太常见的情况,存在替代解决方案:
模型服务#
Ray Serve 非常适合模型组合,使您能够构建由多个 ML 模型和业务逻辑组成的复杂推理服务,所有这些都使用 Python 代码。
它支持复杂的 模型部署模式 需要多个 Ray Actor 的编排,其中不同的 actor 为不同的模型提供推理。Serve 同时处理批处理和在线推理,并且可以扩展到生产中的数千个模型。
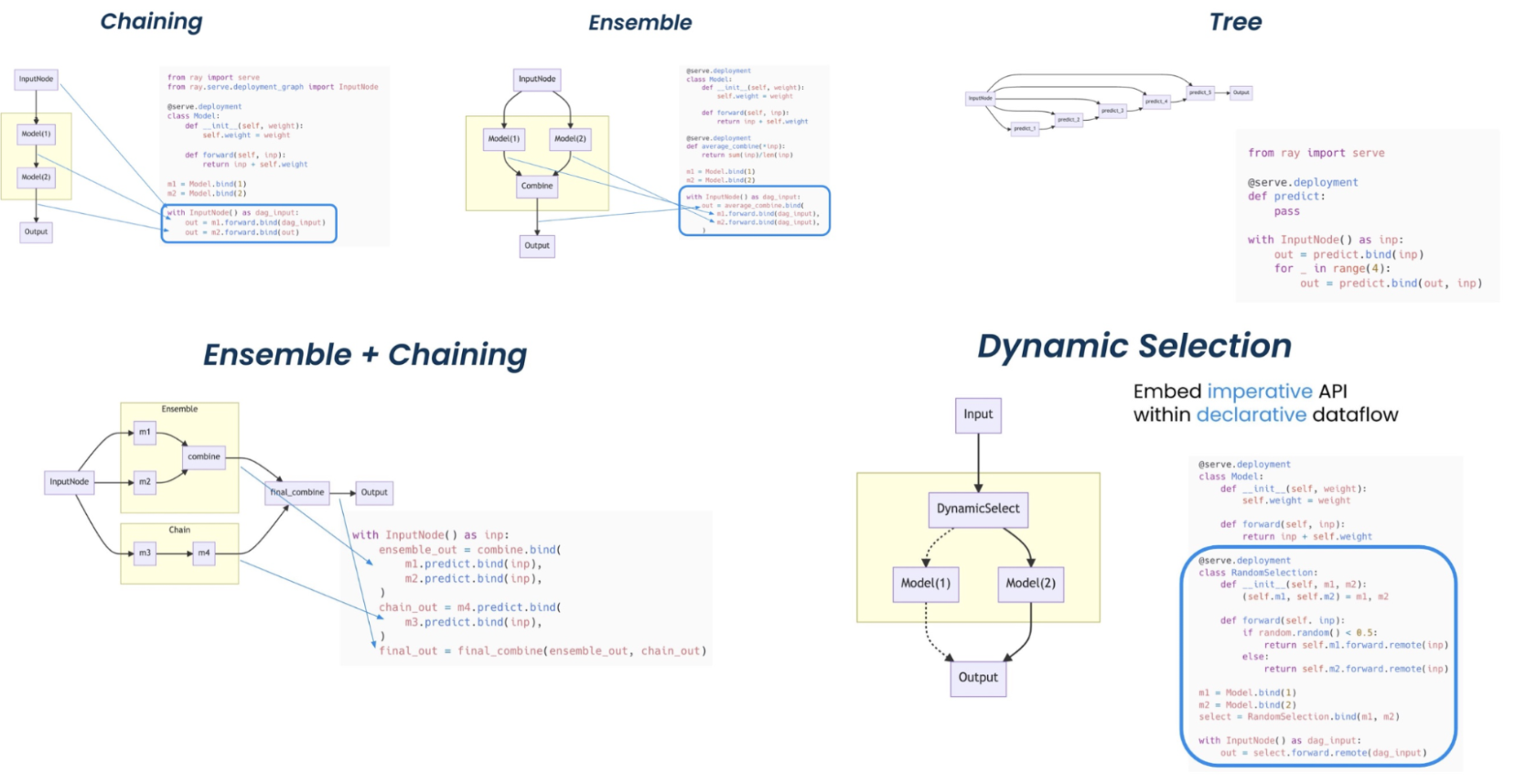
Ray Serve 部署模式。(点击图片放大)#
使用以下资源了解有关模型服务的更多信息。
超参调优#
Ray Tune 类库使任何并行 Ray 工作负载能够在超参数调整算法下运行。
运行多个超参数调整实验是一种适用于分布式计算的模式,因为每个实验彼此独立。Ray Tune 处理了分布式超参数优化的难点,并提供了可用的关键功能,如最佳结果的检查点、优化调度和指定搜索模式。
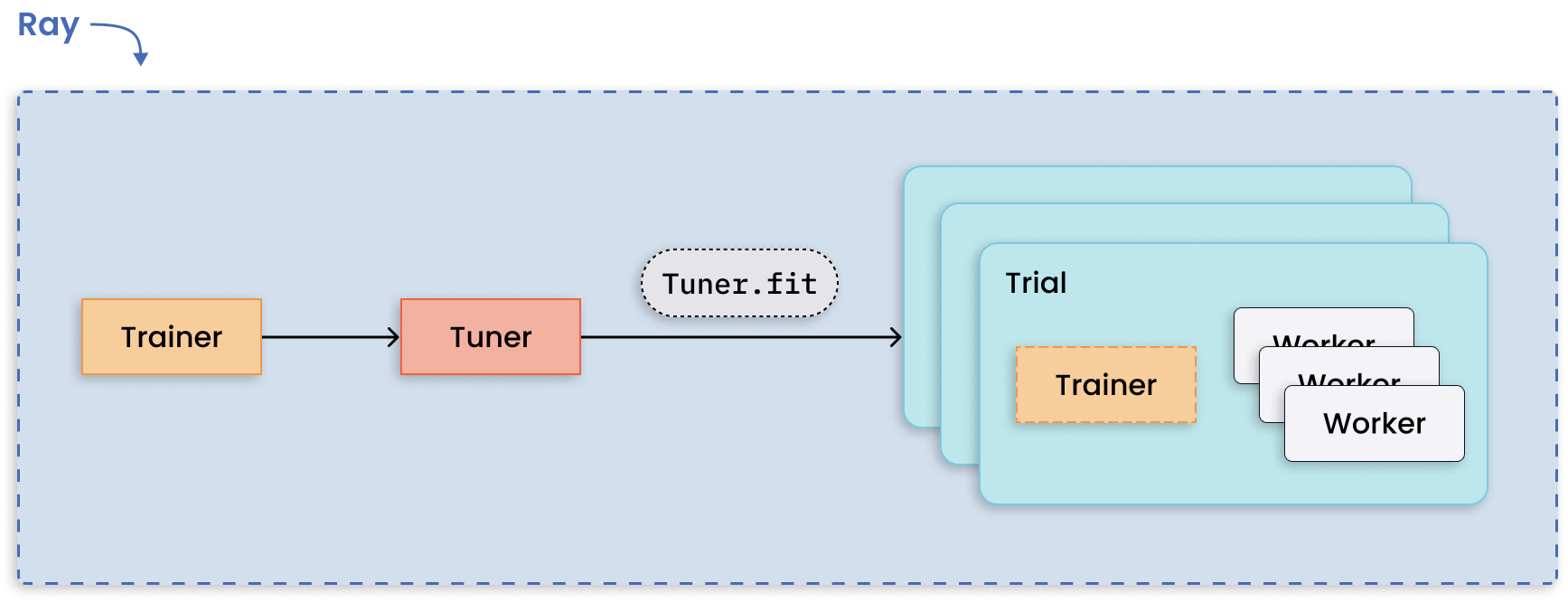
分布式调优和每次试验的分布式训练。#
通过以下讲座和用户指南了解有关 Tune 库的更多信息。
分布式训练#
Ray Train 该库在一个简单的 Trainer API 下集成了许多分布式培训框架, 提供了开箱即用的分布式编排和管理功能。
与训练许多模型不同,模型并行性将一个大模型划分为多台机器进行训练。Ray Train 内置了用于分发模型碎片和并行运行训练的抽象。
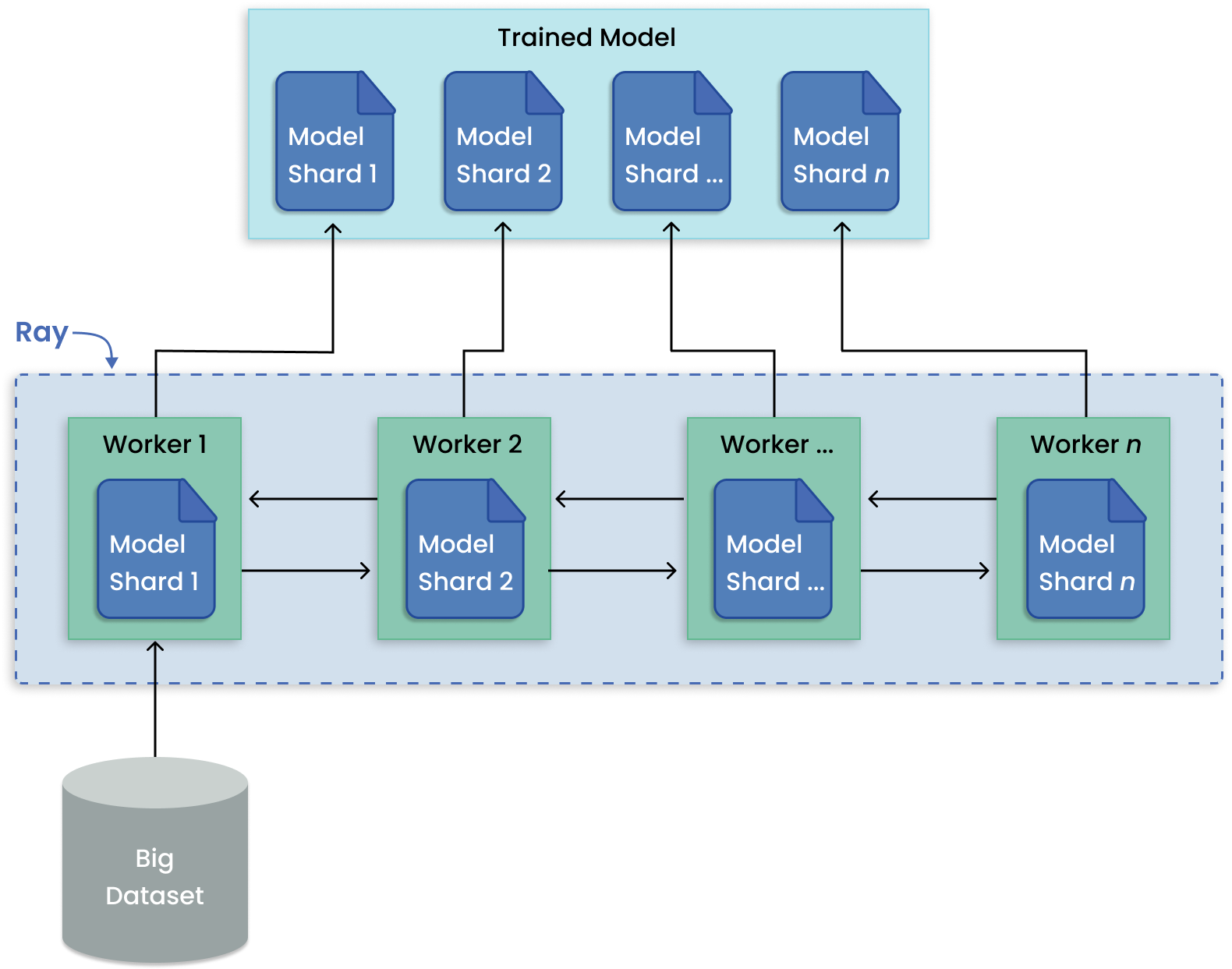
用于分布式大模型训练的模型并行模式。#
通过以下讲座和用户指南了解更多关于 Train 库的信息。
强化学习#
RLlib 是一个强化学习 (RL) 开源类库,为生产级、高度分布式的 RL 工作负载提供支持,同时为各种行业应用程序维护统一而简单的 API。 RLlib 被许多不同垂直领域的行业领导者使用,如气候控制、工业控制、制造和物流、金融、游戏、汽车、机器人、船舶设计等。
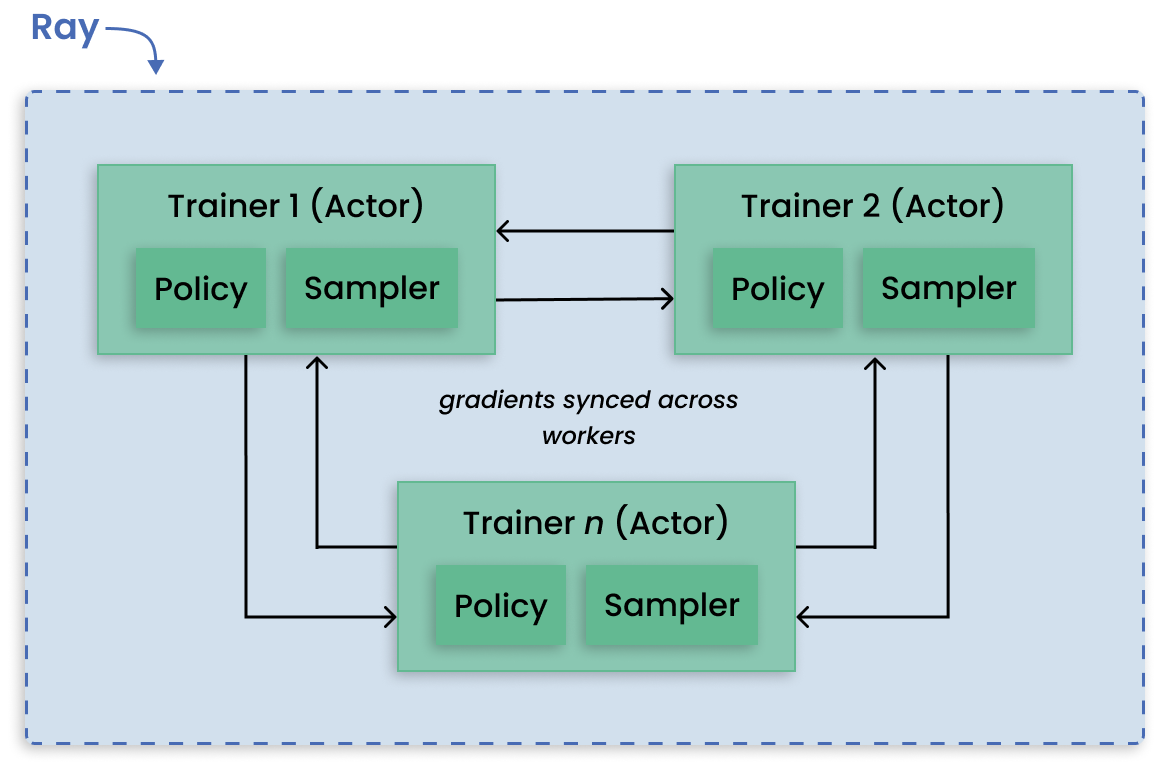
分布式近端优化(DD-PPO)架构。#
使用以下资源了解有关强化学习的更多信息。
ML平台#
Ray 及其人工智能库为希望简化ML平台的团队提供了统一的计算运行时。 Ray 及其库(如 Ray Train、Ray Data 和 Ray Serve)可用于组成端到端ML工作流,为数据预处理提供功能和 API, 作为训练的一部分,并从训练过渡到服务。
在 本章节 中阅读有关使用Ray构建ML平台的更多信息。

端到端 ML 工作流#
以下重点介绍了利用 Ray AI 库实现端到端 ML 工作流的示例。
大规模工作负载编排#
以下重点介绍了利用 Ray Core 的分布式 API 简化大规模工作负载编排的功能项目。