Ray 数据概述
Contents
Ray 数据概述#

Ray Data 是一个可扩展的机器学习数据处理库,特别适用于以下工作负载:
它为分布式数据处理提供灵活且高性能的API:
简单的变换,例如映射 (
map_batches())全局聚合和分组聚合 (
groupby())洗牌操作 (
random_shuffle(),sort(),repartition()).
Ray Data 构建在 Ray 之上,因此它可以有效地扩展到大型集群,并为 CPU 和 GPU 资源提供调度支持。 Ray Data 使用 流式执行 来高效处理大型数据集。
Note
Ray Data 没有 SQL 接口,也不能替代 Spark 等通用 ETL 管道。
为什么选择 Ray Data ?#
对于现代深度学习应用来说更快更便宜
Ray Data 专为涉及 CPU 预处理和 GPU 推理的深度学习应用程序而设计。 通过其强大的流式 数据集 原语,Ray Data 将工作数据从 CPU 预处理任务流式传输到 GPU 推理或训练任务,使您能够同时利用两组资源。
通过使用 Ray Data,您的 GPU 在 CPU 计算期间不再空闲,从而降低批量推理作业的总体成本。
云、架构和数据格式无关
开箱即用的缩放特性
Ray Data 建立在 Ray 之上,因此它可以轻松扩展到许多机器。在一台机器上运行的代码也可以在大型集群上运行,无需任何更改。
Python 优先
借助 Ray Data,您可以直接使用 Python(而不是 YAML 或其他格式)表达推理作业, 从而实现更快的迭代、更轻松的调试和原生开发人员体验。
离线批量推理#
Tip
请联系我们 以获取使用 Ray Data 的帮助,这是业界最快、最便宜的离线批量推理解决方案。
离线批量推理是对一组固定输入数据生成模型预测的过程。 Ray Data 为批量推理提供了高效且可扩展的解决方案,为深度学习应用程序提供更快的执行速度和成本效益。有关如何使用 Ray Data 进行离线批量推理的更多详细信息,请参阅 批量推理用户指南 。
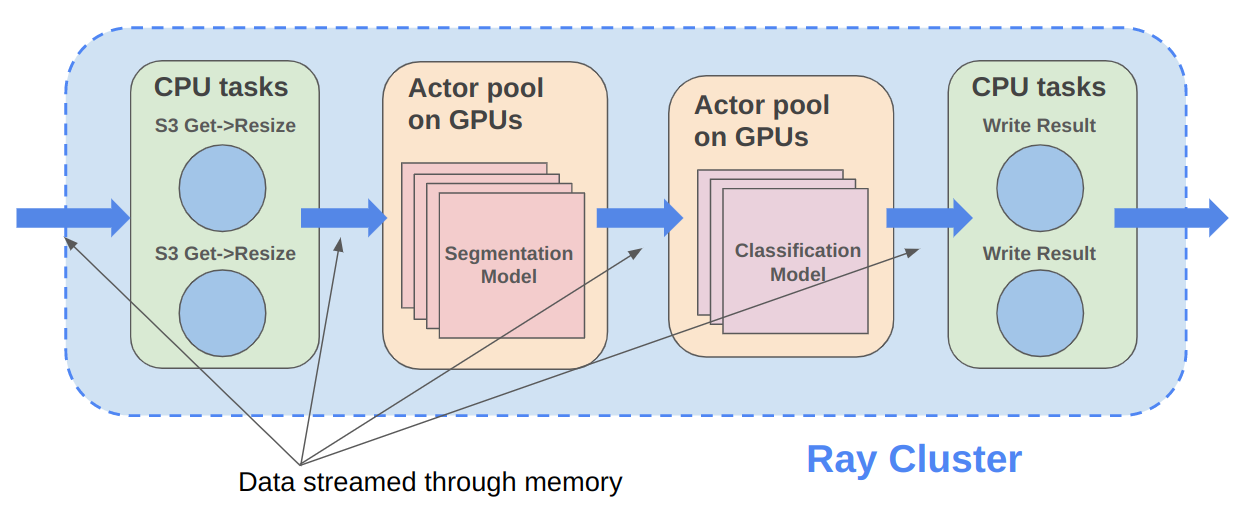
Ray Data 与离线推理 X 相比如何?#
批处理服务: AWS Batch 、 GCP Batch
AWS、GCP 和 Azure 等云提供商提供批处理服务来为您管理计算基础设施。每个服务都使用相同的流程:您提供代码,服务在集群中的每个节点上运行您的代码。然而,虽然基础设施管理是必要的,但通常还不够。这些服务具有局限性,例如缺乏软件库来解决优化并行化、高效数据传输和易于调试的问题。这些解决方案仅适合有经验的用户,他们可以编写自己的优化批量推理代码。
Ray Data 不仅抽象了基础设施管理,还抽象了数据集的分片、这些分片上推理的并行化以及数据从存储到 CPU 到 GPU 的传输。
在线推理解决方案: Bento ML 、 Sagemaker Batch Transform
Bento ML 、 Sagemaker Batch Transform 、Ray Serve 等解决方案提供了 API ,让你可以轻松编写高性能推理代码,并消除基础设施的复杂性。
但它们是为在线推理而不是离线批量推理而设计的,这是具有不同要求的两个不同问题。这些解决方案引入了额外的复杂性(如 HTTP),并且无法有效处理大型数据集,导致 Bento ML 等推理服务提供商 无法与 Apache Spark 集成 以进行离线推理。
Ray Data 专为离线批处理作业而构建,无需启动服务器或发送 HTTP 请求的所有额外复杂性。
有关 Ray Data 和 Sagemaker Batch Transform 之间更详细的性能比较,请参阅 离线批量推理:比较 Ray、Apache Spark 和 SageMaker 。
分布式数据处理框架: Apache Spark
Ray Data 处理许多与 Apache Spark 相同的批处理工作负载,但具有更适合深度学习推理的 GPU 工作负载的流范例。
有关 Ray Data 和 Apache Spark 之间更详细的性能比较,请参阅 离线批量推理:比较 Ray、Apache Spark 和 SageMaker 。
批量推理案例研究#
ML 训练的预处理和摄取#
使用 Ray Data 以流方式加载和预处理分布式 ML training pipelines 的数据。 Ray Data 充当从存储或 ETL 管道输出到 Ray 中的分布式应用程序和库的最后一英里桥梁。 不要将其用作更通用的数据处理系统的替代品。 有关如何使用 Ray Data 进行预处理和摄取以进行 ML 训练的更多详细信息,请参阅 ML 训练的数据加载 。
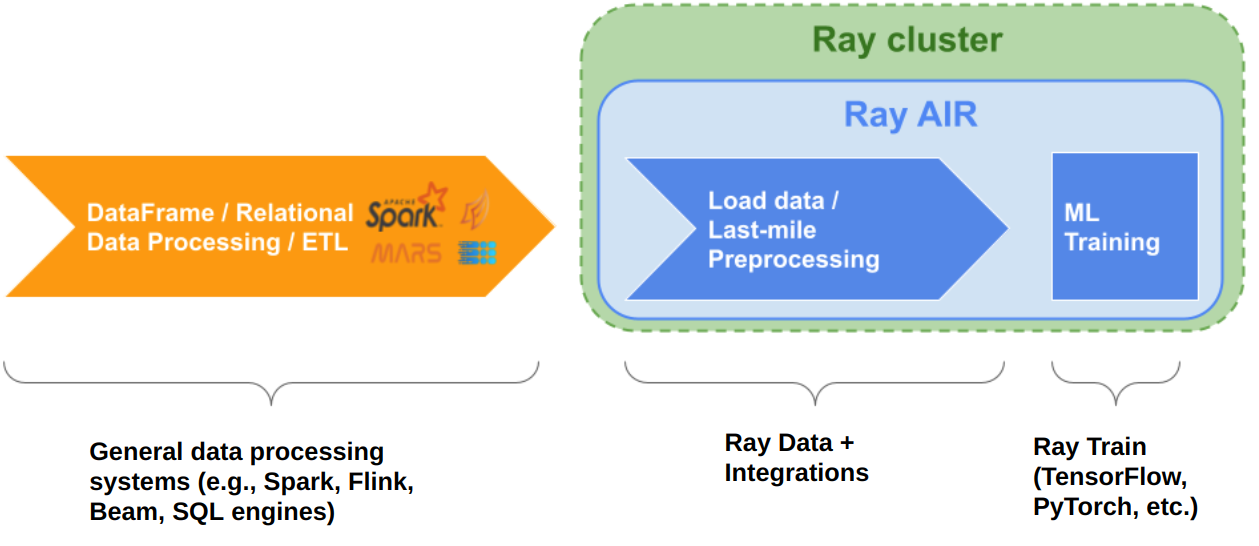
Ray Data 与 ML 训练摄取的 X 相比如何?#
PyTorch Dataset 和 DataLoader
与框架无关: 数据集与框架无关,并且可以在不同的分布式训练框架之间移植,而 Torch datasets 特定于 Torch。
无内置 IO 层: Torch 数据集没有用于常见文件格式或与其他框架进行内存交换的 I/O 层;用户需要引入其他库并自行进行此集成。
通用分布式数据处理: 数据集更通用:它可以处理通用分布式操作,包括全局 per-epoch shuffling,,否则必须通过将两个单独的系统拼接在一起来实现。 Torch 数据集需要这样的拼接来处理比基于批处理的预处理更复杂的事情,并且本身不支持跨工作分片的 shuffling 。 请参阅我们的 博文 ,了解为什么这种共享基础设施对于第三代 ML 架构很重要。
较低的开销: 数据集的开销较低:与 Torch 数据集基于多处理的管道相比,它支持进程之间的零拷贝交换。
TensorFlow Dataset
与框架无关: 数据集与框架无关,并且可以在不同的分布式训练框架之间移植, TensorFlow datasets 特定于 TensorFlow。
统一单节点和分布式: 数据集在同一抽象下统一单节点和多节点训练。 TensorFlow 数据集提出了分布式数据加载的 独立概念 ,并阻止代码无缝扩展到更大的集群。
通用分布式数据处理: 数据集更通用:它可以处理通用分布式操作,包括全局每纪元洗牌,否则必须通过将两个单独的系统拼接在一起来实现。 TensorFlow 数据集需要这样的拼接来完成比基本预处理更复杂的事情,并且本身不支持跨工作分片的完全洗牌;仅支持文件交错。请参阅我们的 博文 ,了解为什么这种共享基础设施对于第三代 ML 架构很重要。
较低的开销: 数据集的开销较低:与 TensorFlow 数据集基于多处理的管道相比,它支持进程之间的零拷贝交换。
Petastorm
支持的数据类型: Petastorm 仅支持 Parquet 数据,而 Ray Data 支持多种文件格式。
较低的开销: 数据集的开销较低:与 Petastorm 使用的基于多处理的管道相比,它支持进程之间的零拷贝交换。
无数据处理: Petastorm 不公开任何数据处理 API。
NVTabular
支持的数据类型: NVTabular 仅支持表格(Parquet、CSV、Avro)数据,而 Ray Data 支持许多其他文件格式。
较低的开销: 数据集的开销较低:与 Petastorm 使用的基于多处理的管道相比,它支持进程之间的零拷贝交换。
无数据处理: NVTabular 不支持在数据集转换中混合异构资源(例如CPU 和GPU 转换),而Ray Data 支持这一点。