Ray 仪表盘
Contents
Ray 仪表盘#
Ray 提供了一个基于 Web 的仪表板,用于监视和调试 Ray 应用程序。系统状态的可视化表示允许用户跟踪应用程序的性能并解决问题。
设置仪表板#
要访问仪表板,请使用 ray[default] 或包含 Ray 仪表板组件的 其他安装命令 。例如:
pip install -U "ray[default]"
当您在笔记本电脑上启动单节点 Ray 集群时,可以使用 Ray 初始化时打印的 URL(默认 URL 为 **http://localhost:8265**5)或使用 ray.init 返回的上下文对象来访问仪表板。
import ray
context = ray.init()
print(context.dashboard_url)
127.0.0.1:8265
INFO worker.py:1487 -- Connected to Ray cluster. View the dashboard at 127.0.0.1:8265.
Note
如果在 docker 容器中启动 Ray, --dashboard-host 是必需参数。例如, ray start --head --dashboard-host=0.0.0.0。
当使用 虚拟机集群启动器, KubeRay 控制器,或手动配置启动远程 Ray 集群, Ray 仪表盘在头节点上启动,但仪表板端口可能不会公开暴露。查看 配置仪表盘 了解如何从头节点外部查看仪表板。
Note
使用 Ray Dashboard 时,强烈建议同时设置 Prometheus 和 Grafana。 它们对于 Metrics View ,了解如何将 Prometheus 和 Grafana 与 Ray Dashboard 集成。
浏览视图#
仪表板有多个称为视图的选项卡。根据您的目标,您可以使用一种或多种视图的组合:
作业视图#
作业视图可让您监控 Ray Cluster 上运行的不同作业。
Ray Job 是使用 Ray API(例如 ray.init)的 Ray 工作负载。建议通过 :ref:`Ray Job API <jobs-quickstart>`将作业提交到集群。您还可以交互地运行 Ray 作业(例如,通过在头节点内执行 Python 脚本)。
作业视图显示活动、已完成和失败作业的列表,单击 ID 允许用户查看有关该作业的详细信息。 有关 Ray 作业的更多信息,请参阅 Ray 作业概述部分。
Job 概况#
您可以通过单击“堆栈跟踪”或“CPU 火焰图”操作来分析 Ray 作业。有关更多详细信息,请参阅:ref:Profiling。
任务和 actor 细分#

作业视图按状态细分任务和 actor。 默认情况下,任务和 actor 是分组和嵌套的。您可以通过单击展开按钮来查看嵌套条目。
任务和 actor 使用以下标准进行分组和嵌套:
A所有task 和 actor都分组在一起。通过展开相应的行来查看各个条目。
T任务按其
name属性分组(例如,task.options(name="<name_here>").remote())。子任务(嵌套任务)嵌套在其父任务行下。
Actors 按他们的类名分组。
子 Actors(在 Actor 内创建的 Actor)嵌套在其父 Actor 的行下。
Actor 任务(Actor 内的远程方法)嵌套在相应 Actor 方法的 Actor 下。
Note
作业详细信息页面只能显示或检索每个作业最多 10K 个任务。对于任务数超过 10K 的作业,超出 10K 限制的任务部分不予计算。未计入任务的数量可从任务细分中获得。
任务时间线#
首先,单击下载按钮下载 chrome 跟踪文件。或者,您可以 使用 CLI 或 SDK 导出跟踪文件。
其次,使用 chrome://tracing 或者 Perfetto UI 等工具并拖拽下载的 chrome 跟踪文件。我们将使用 Perfetto,因为它是可视化 chrome 跟踪文件的推荐方法。
在 Ray Tasks 和 Actors 的时间线可视化中,有 Node 行(硬件)和 Worker 行(进程)。 每个 worker 行显示该 worker 随时间发生的任务事件列表(例如,计划的任务、运行的任务、输入/输出反序列化等)。
Ray 状态#
作业视图显示 Ray Cluster 的状态。此信息是 CLI 命令 ray status 的输出。
左侧面板显示自动缩放状态,包括挂起、活动和失败的节点。右侧面板显示资源需求,即当前无法调度到集群的资源。此页面对于调试资源死锁或缓慢的调度很有用。
Note
输出显示整个集群的聚合信息(不是按作业)。如果您运行多个作业,则某些需求可能来自其他作业。
任务、actor 和 占位组#
仪表板显示作业任务、actor 和 占位组的状态表。 该信息是 Ray State APIs 输出的。
您可以展开该表以查看每个任务、actor 和 占位组的列表。
服务视图#
查看您的常规 Serve 配置、Serve 应用程序列表,如果您配置了 Grafana 和 Prometheus , 还可以查看 Serve 应用程序的高级指标。单击服务应用程序名称,进入服务应用程序详细信息页面。
提供应用程序详细信息页面#
查看 Serve 应用程序的配置和元数据以及 Serve 部署和副本 的列表。 单击部署的展开按钮以查看副本。
每个部署都有两个可用的操作。您可以查看部署配置,如果您配置了 Grafana 和 Prometheus ,则可以打开 Grafana 仪表板,其中包含有关该部署的详细指标。
对于每个副本,有两个可用的操作。您可以查看该副本的日志,如果您配置了 Grafana 和 Prometheus ,则可以打开 Grafana 仪表板,其中包含有关该副本的详细指标。单击副本名称,进入服务副本详细信息页面。
服务副本详细信息页面#
此页面显示有关服务副本的元数据、有关副本的高级指标,如果您配置了 Grafana 和 Prometheus ,以及该副本已完成 Tasks 的历史记录。
Serve 指标#
Ray Serve 导出各种时间序列指标,以帮助您了解 Serve 应用程序随时间变化的状态。 在 此处 查找有关这些指标的更多详细信息。 要存储和可视化这些指标,请按照 这里 说明设置 Prometheus 和 Grafana 。
这些指标可在 Ray Dashboard 的“服务”页面和“服务副本详细信息”页面中找到。 它们也可以作为 Grafana 仪表板进行访问。 在 Grafana 仪表板中,使用顶部的下拉筛选器按路由、部署或副本筛选指标。 将鼠标悬停在每个图表左上角的“信息”图标上即可获得每个图表的准确描述。
集群视图#
Cluster 视图是机器(节点)和 Workers(进程)层次关系的可视化。 每台主机由许多 Worker 组成,您可以通过单击 + 按钮查看。 另请参阅将 GPU 资源分配给特定的 Actor 或任务。
单击节点 ID,可查看节点详细信息页面。
此外,机器视图允许您查看节点或工作线程的 日志。
Actors 视图#
使用 Actors 视图查看 Actor 的日志以及哪个作业创建了该 Actor。
最多存储 1000 个死亡 Actor 的信息。
Ray 启动时覆盖该 RAY_DASHBOARD_MAX_ACTORS_TO_CACHE 环境变量。
Actor 性能#
在正在运行的 Actor 上运行分析器。有关更多详细信息,请参阅 Dashboard Profiling 。
Actor 详情页#
单击 ID,可查看 Actor 的详细信息视图。
在 Actor 详细信息页面上,查看元数据、状态以及所有已运行的 Actor 任务。
指标视图#
Ray 导出可从 “指标”视图 中获得的默认指标。以下是一些可用的示例指标。
Ta按状态细分的任务、actor 和 占位组
跨节点 L辑资源使用情况
跨节点硬件资源使用情况
Autoscaler 状态
有关可用指标,请参阅 系统指标页 。
Note
Metrics 视图需要 Prometheus 和 Grafana 设置。请参阅 :ref:`配置和管理仪表板 <observability-visualization-setup>`以了解如何设置 Prometheus 和 Grafana。
Metrics 视图提供 Ray 发出的时间序列指标的可视化。
您可以在右上角选择指标的时间范围。图表每 15 秒自动刷新一次。
还有一个方便的按钮可以从仪表板打开 Grafana UI。 Grafana UI 提供了图表的额外可定制性。
分析Tasks和Actors的CPU和内存使用情况#
仪表板中的 标视图 提供了“每个组件的 CPU/内存使用情况图表”,显示应用程序(以及系统组件)中每个task 和 actor随时间的 CPU 和内存使用情况。 您可以识别可能消耗比预期更多资源的task 和 actor,并优化应用程序的性能。
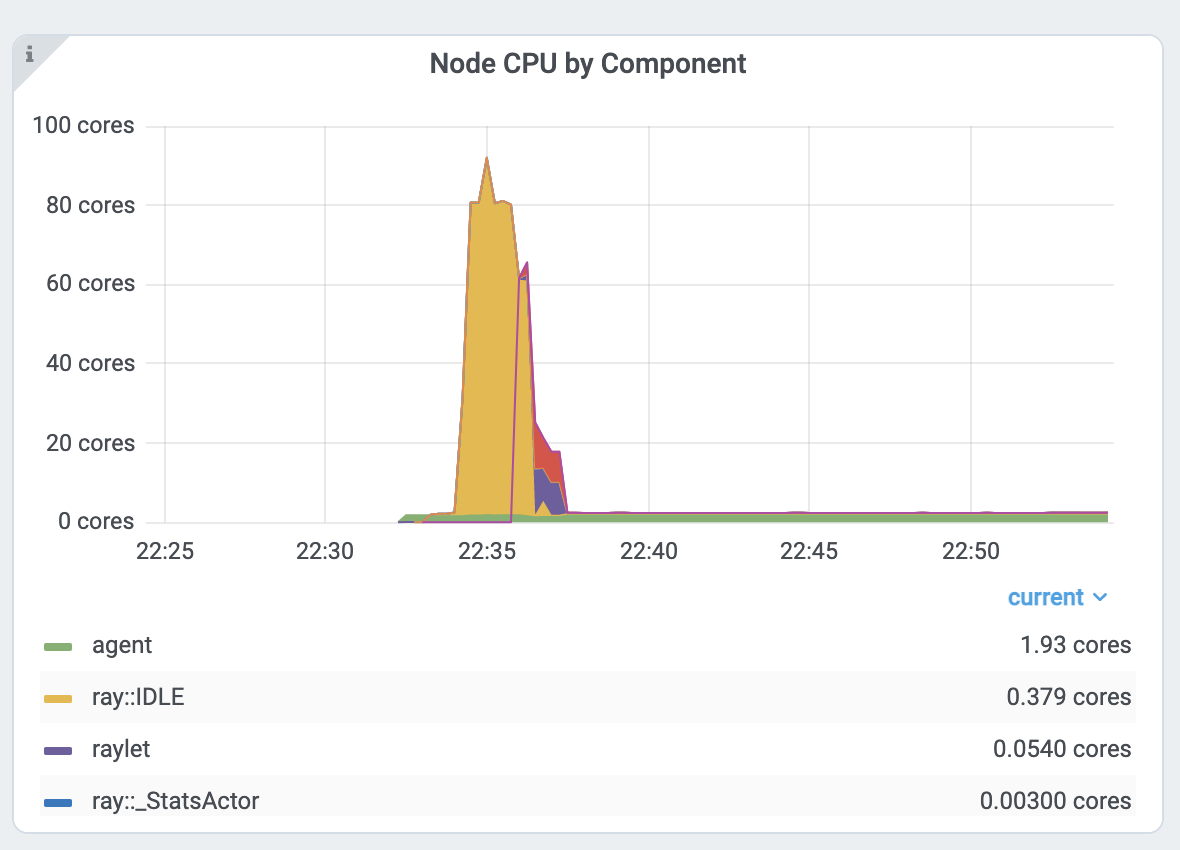
每个组件 CPU 图表。 0.379个核心意味着它使用了单个CPU核心的40%。 以 ray::. raylet, agent、dashboard、gcs 进程名称开头的是系统组件。
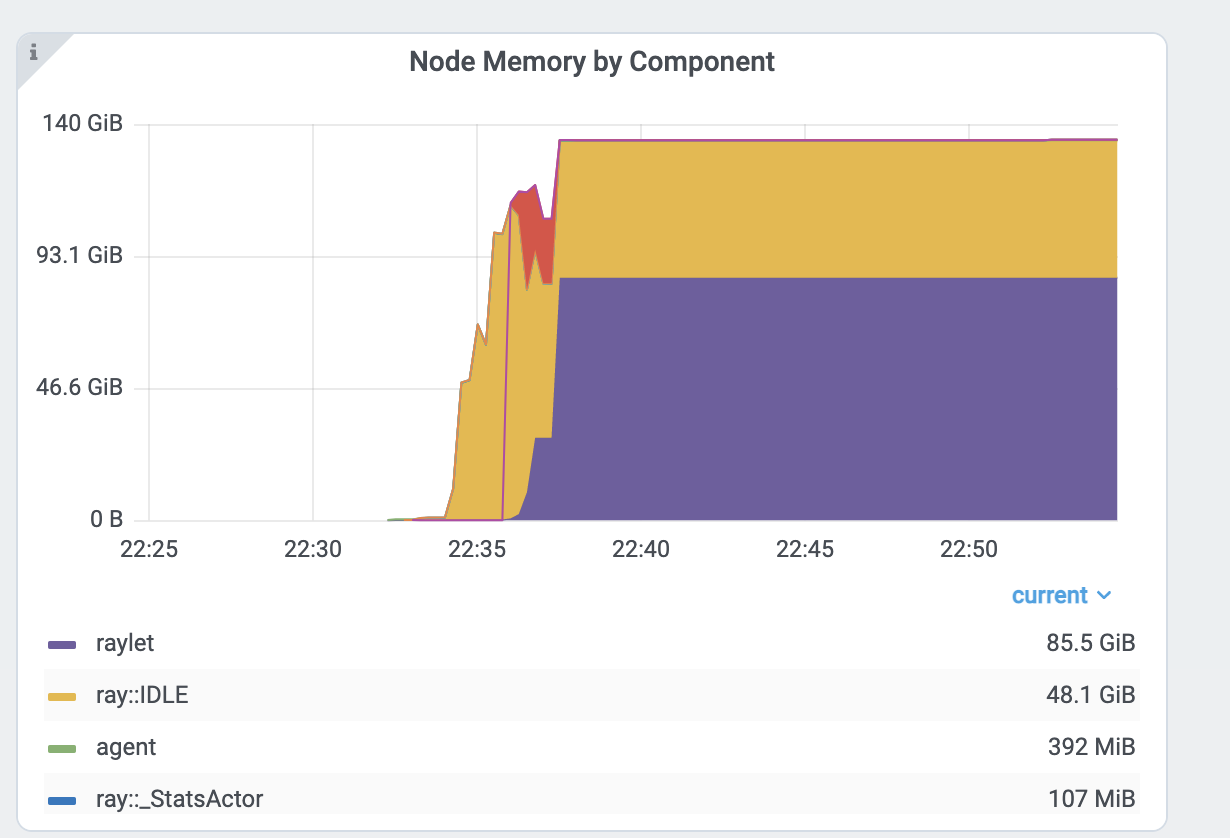
每个组件的内存图。以 ray::. raylet, agent, dashboard, or gcs 程名称开头的是系统组件。
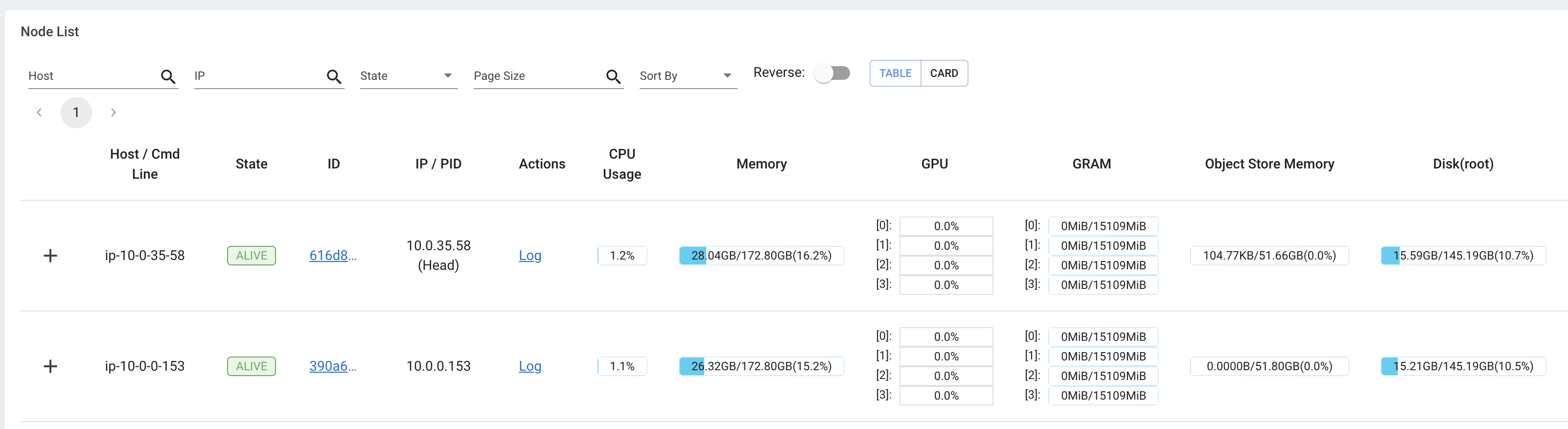
此外,用户还可以从 集群视图 中查看硬件利用率的快照,,该视图提供了整个 Ray 集群的资源使用情况概览。
查看资源利用率#
Ray 要求用指定 资源 数量,以及 Tasks 和 Actors 通过 num_cpus、 num_gpus、 memory 和 resource 等参数指定资源数量.
这些值用于调度,但可能并不总是与实际资源利用率(物理资源利用率)匹配。
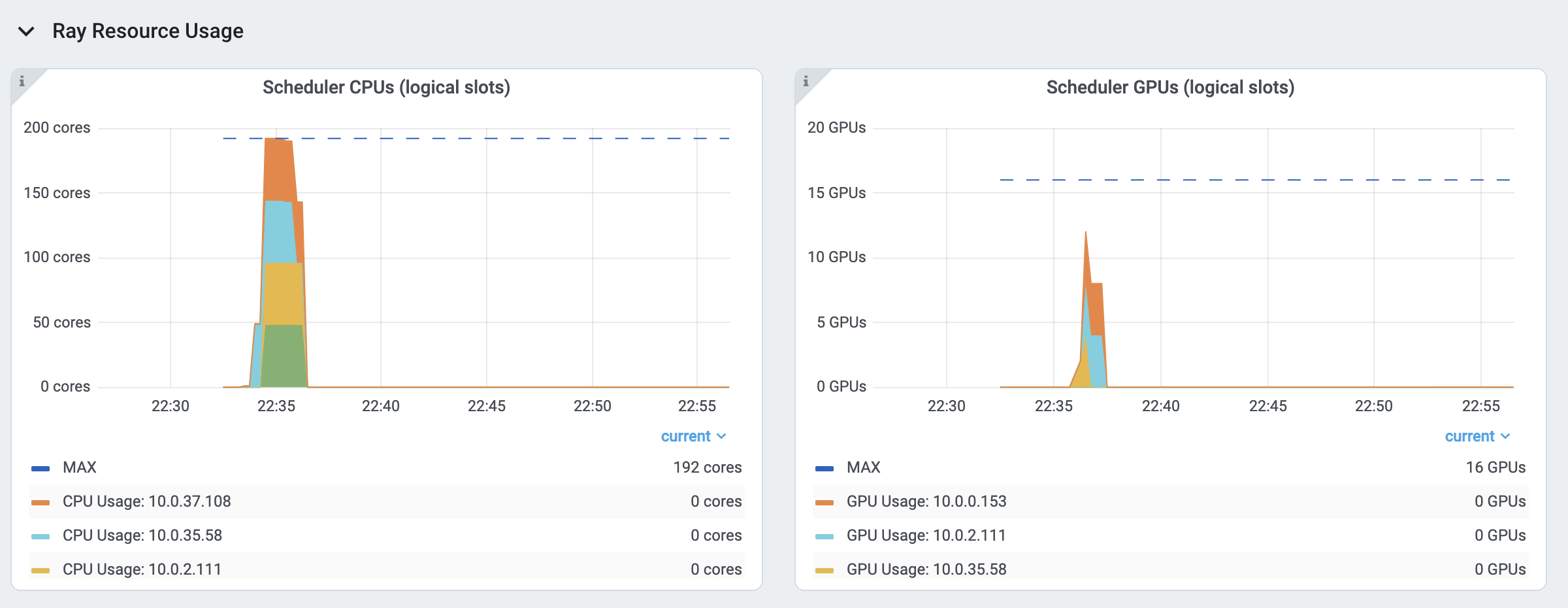
逻辑资源 使用率。
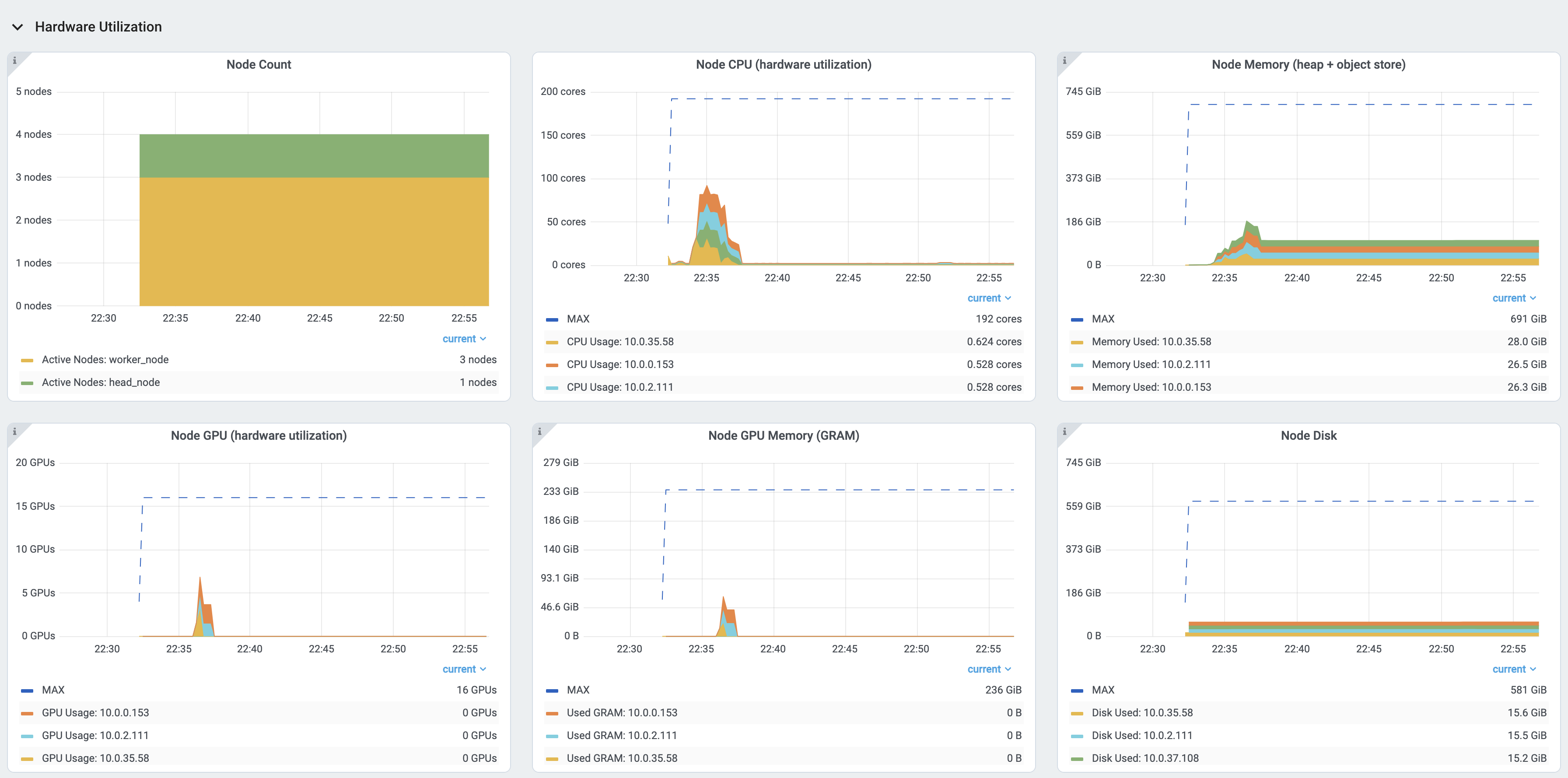
物理资源(硬件)使用情况。 Ray 提供集群中每台机器的 CPU、GPU、内存、GRAM、磁盘和网络使用情况。
日志视图#
日志视图列出了集群中的 Ray 日志。它按节点和日志文件名组织。其他页面中的许多日志链接都链接到此视图并过滤列表,以便显示相关日志。
要了解 Ray 的日志记录结构,请参阅 志记录目录和文件结构。
日志视图提供搜索功能来帮助您查找特定日志消息。
驱动器日志
如果 Ray 作业是通过 Job API 提交的,则可以从仪表板获取作业日志。日志文件遵循以下格式: job-driver-<job_submission_id>.log。
如果直接在 Ray 集群的头节点上执行驱动程序(不使用作业 API)或使用 Ray 客户端 运行,则无法从仪表板访问驱动程序日志。在这种情况下,请查看终端或 Jupyter Notebook 输出以查看驱动程序日志。
Task 和 Actor 日志 (Worker 日志)
Task 和 Actor 日志通过 Task 和 Actor 表视图。单击“日志”按钮。
您可以查看包含从任务和 actor 发出的输出的 stdout 和 stderr 日志。
对于Actors,还可以查看对应Worker进程的系统日志。
Note
异步 Actor 任务或线程 Actor 任务(并发度>1)的日志仅作为 Actor 日志的一部分提供。按照仪表板中的说明查看 Actor 日志。
Task 和 Actor 错误
您可以通过查看作业进度栏轻松识别失败的任务或 actor。
task 和 actor表分别显示失败的task 或 actor的名称。它们还提供对相应日志或错误消息的访问。
概览视图#
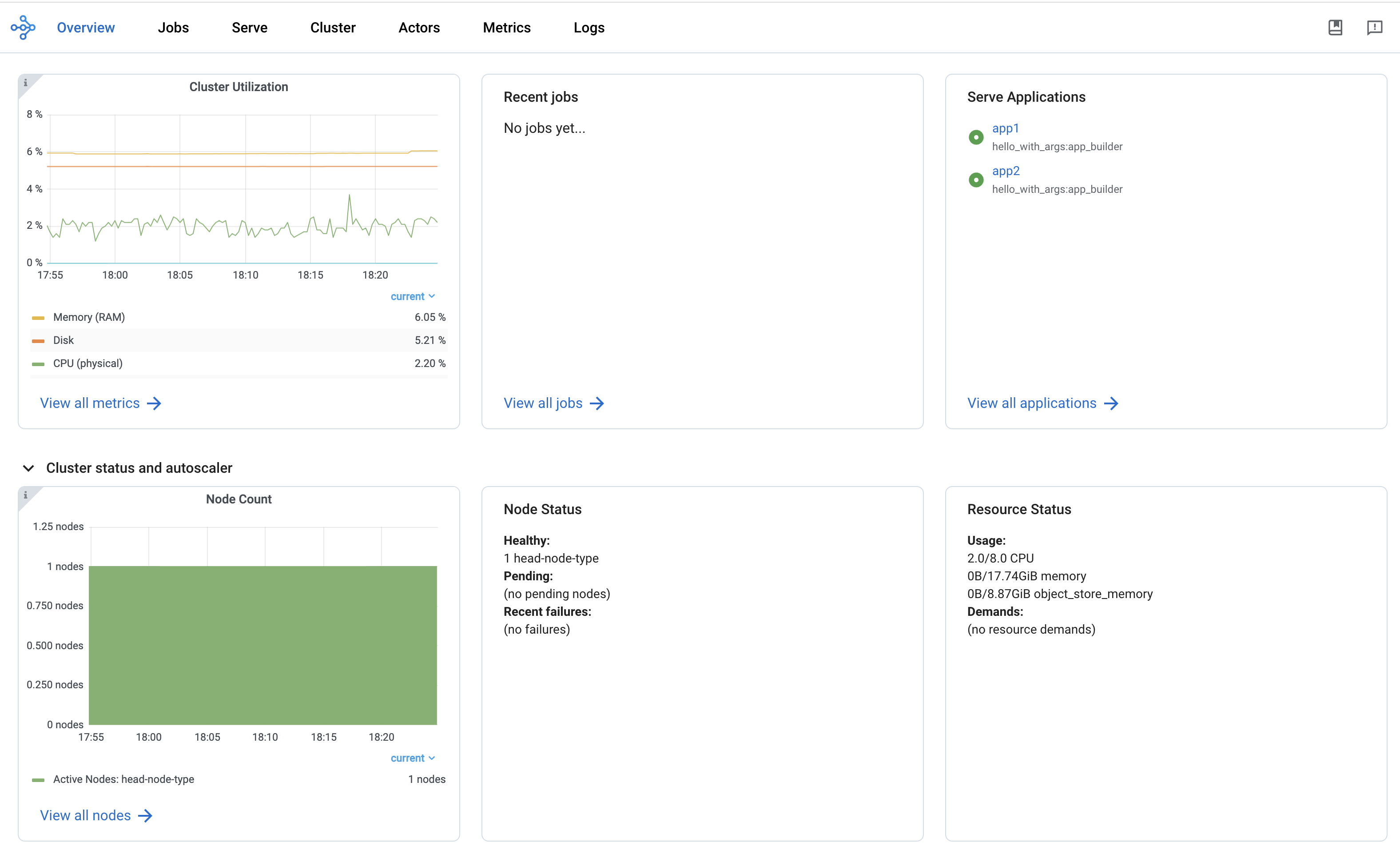
概览视图提供了 Ray Cluster 的高级状态。
概览指标
概览指标页面提供集群级别的硬件利用率和自动缩放状态(待处理、活动和故障节点的数量)。
最近的 Job
最近的作业窗格提供了最近提交的 Ray 作业的列表。
Serve 应用
“服务应用程序”窗格提供最近部署的服务应用程序的列表
时间视图
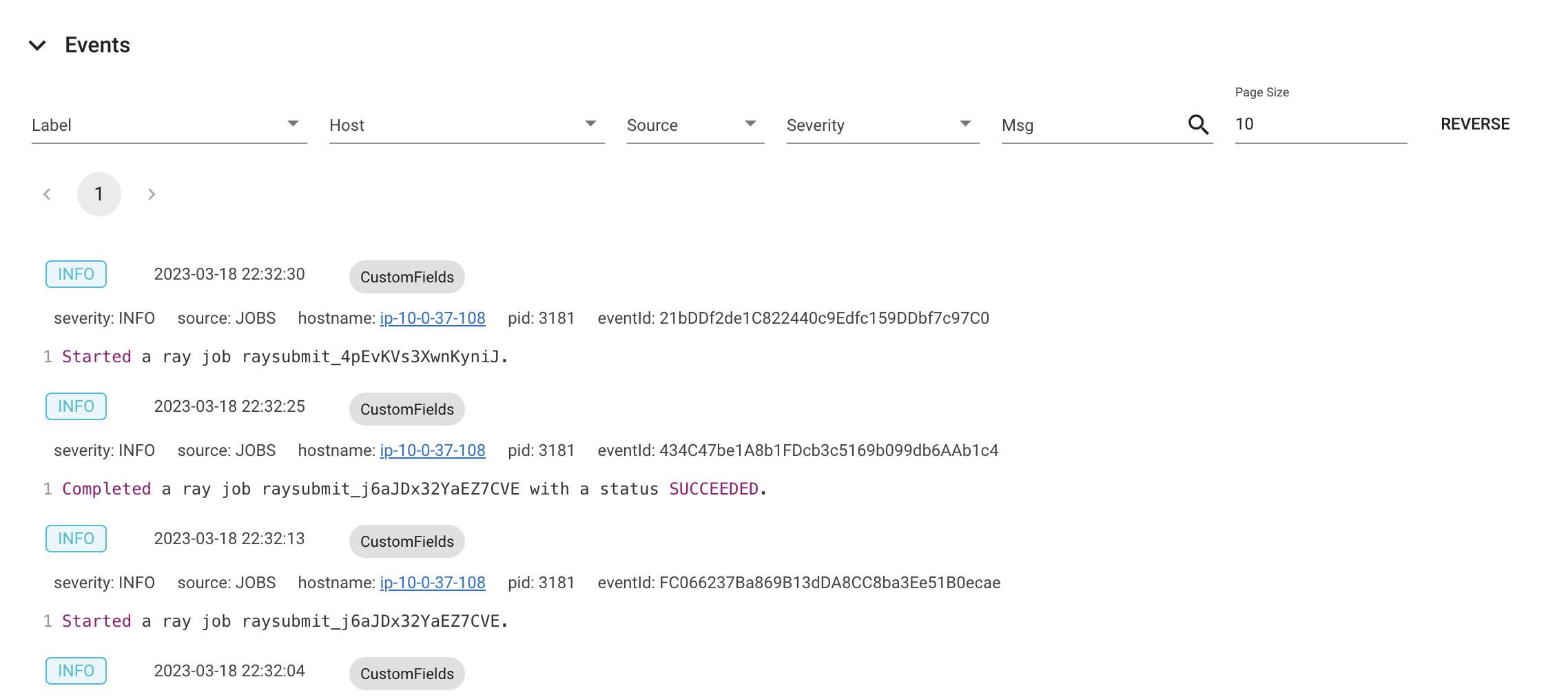
事件视图按时间顺序显示与特定类型(例如,自动缩放器或作业)关联的事件列表。
可以使用 (Ray state APIs) 的 CLI 命令 ray list cluster-events 访问相同的信息。
有两种类型的事件可用:
Job: 与 :ref:`Ray Jobs API <jobs-quickstart>`相关的事件。
Autoscaler: Ray autoscaler 相关事件。