通过示例简单介绍 Ray Core
Contents
通过示例简单介绍 Ray Core#
在 Ray Core 中实现一个函数,以了解 Ray 的工作原理及其基本概念。 无论是经验较少的 Python 程序员还是对高级任务感兴趣的 Python 程序员, 都可以通过学习 Ray Core API 开始使用 Python 进行分布式计算。
安装 Ray#
使用以下命令安装 Ray:
! pip install ray
Ray Core#
通过运行以下命令启动本地集群:
import ray
ray.init()
请注意输出中的以下几行:
... INFO services.py:1263 -- View the Ray dashboard at http://127.0.0.1:8265
{'node_ip_address': '192.168.1.41',
...
'node_id': '...'}
这些消息表明 Ray 集群正在按预期工作。在此示例输出中,Ray 仪表板的地址为 http://127.0.0.1:8265. 。通过输出第一行的地址访问 Ray 仪表板。Ray 仪表板显示可用 CPU 核心数和当前 Ray 应用程序的总利用率等信息。
这是笔记本电脑的典型输出:
{'CPU': 12.0,
'memory': 14203886388.0,
'node:127.0.0.1': 1.0,
'object_store_memory': 2147483648.0}
接下来,我们简单介绍一下 Ray Core API,也就是我们所说的 Ray API。 Ray API 建立在 Python 程序员熟悉的装饰器、函数和类等概念之上。 它是分布式计算的通用编程接口。 引擎处理复杂的工作,让开发人员可以将 Ray 与现有的 Python 库和系统一起使用。
您的第一个 Ray API 示例#
以下函数从数据库中检索和处理数据。虚拟变量是一个简单的 Python 列表,其中包含 “Learning Ray” book 书记的标题的 database。
sleep 函数暂停一段时间以模拟从数据库访问和处理数据的成本。
import time
database = [
"Learning", "Ray",
"Flexible", "Distributed", "Python", "for", "Machine", "Learning"
]
def retrieve(item):
time.sleep(item / 10.)
return item, database[item]
如果索引为 5 的项目需要半秒, (5 / 10.),则按顺序检索所有八个项目的总运行时间估计为 (0+1+2+3+4+5+6+7)/10. = 2.8 秒。
运行以下代码以获取实际时间:
def print_runtime(input_data, start_time):
print(f'Runtime: {time.time() - start_time:.2f} seconds, data:')
print(*input_data, sep="\n")
start = time.time()
data = [retrieve(item) for item in range(8)]
print_runtime(data, start)
Runtime: 2.82 seconds, data:
(0, 'Learning')
(1, 'Ray')
(2, 'Flexible')
(3, 'Distributed')
(4, 'Python')
(5, 'for')
(6, 'Machine')
(7, 'Learning')
在此示例中,运行该函数的总时间为 2.82 秒,但您的计算机的时间可能有所不同。 请注意,此基本 Python 版本无法同时运行该函数。
您可能认为 Python 列表推导更高效。测量的运行时间为 2.8 秒,这实际上是最坏情况。 尽管此程序在大部分运行时间内处于“休眠”状态,但由于全局解释器锁 (GIL),它运行速度很慢。
Ray 任务#
此任务可以从并行化中受益。如果它完美分布,则运行时间不应比最慢的子任务花费的时间长得多,即 7/10. = 0.7 秒。
扩展此示例以在 Ray 上并行运行,请首先使用 @ray.remote 装饰器:
import ray
@ray.remote
def retrieve_task(item):
return retrieve(item)
使用装饰器,函数 retrieve_task 编程 :ref:ray-remote-functions<Ray task>_。
Ray 任务是 Ray 在与调用它的地方不同的进程上执行的函数,也可能是在不同的机器上执行的函数。
Ray 使用起来很方便,因为您可以继续编写 Python 代码,而无需大幅改变您的方法或编程风格。
在检索函数上使用使用 :func:ray.remote()<@ray.remote> 装饰器是装饰器的预期用途,并且您在此示例中没有修改原始代码。
要检索数据库条目并测量性能,您无需对代码进行太多更改。以下是该过程的概述:
start = time.time()
object_references = [
retrieve_task.remote(item) for item in range(8)
]
data = ray.get(object_references)
print_runtime(data, start)
2022-12-20 13:52:34,632 INFO worker.py:1529 -- Started a local Ray instance. View the dashboard at 127.0.0.1:8265
Runtime: 2.82 seconds, data:
(0, 'Learning')
(1, 'Ray')
(2, 'Flexible')
(3, 'Distributed')
(4, 'Python')
(5, 'for')
(6, 'Machine')
(7, 'Learning')
并行运行任务需要对代码进行两处小修改
要远程执行 Ray 任务,您必须使用 .remote() 调用。
Ray 异步执行远程任务,即使在本地集群上也是如此。
代码片段中的 object_references 列表不直接包含结果。
如果使用 type(object_references[0])检查第一个项目的 Python 类型,
您会发现它实际上是一个 ObjectRef。
这些对象引用对应于您 未来 要请求的结果。
:func:ray.get()<ray.get(...)> 用于请求结果。 每当您在 Ray 任务上调用远程时,
它都会立即返回一个或多个对象引用。
将 Ray 任务视为创建对象的主要方式。
以下部分是一个将多个任务链接在一起并允许 Ray 在它们之间传递和解析对象的示例。
让我们回顾一下前面的步骤。
从一个 Python 函数开始,然后用 @ray.remote 装饰,使该函数成为 Ray 任务。
代替直接在代码中调用原始函数,而是调用 .remote(...) Ray 任务。
最后,使用 .get(...) 从 Ray 集群中检索结果。
考虑从您自己的一个函数创建一个 Ray 任务作为额外的练习。
让我们回顾一下使用 Ray 任务所带来的性能提升。 在大多数笔记本电脑上,运行时间约为 0.71 秒,略高于最慢的子任务(0.7 秒)。 您可以通过利用更多 Ray 的 API 来进一步改进程序。
对象存储#
检索定义直接访问来自项目的 database。 虽然这在本地 Ray 集群上运行良好,但请考虑它在具有多台计算机的实际集群上如何运行。
Ray 集群有一个带有驱动程序进程的头节点和多个带有执行任务的工作进程的 worker 节点。
在这种情况下,数据库仅在驱动程序上定义,但工作进程需要访问它才能运行检索任务。
Ray 在驱动程序和工作程序之间或工作程序之间共享对象的解决方案是使用函数
ray.put 将数据放入 Ray 的分布式对象存储中。
在 retrieve_task 定义中,您可以添加一个 db 参数,稍后作为对象传递 db_object_ref 对象。
db_object_ref = ray.put(database)
@ray.remote
def retrieve_task(item, db):
time.sleep(item / 10.)
return item, db[item]
通过使用对象存储,您可以让 Ray 管理整个集群的数据访问。
虽然对象存储涉及一些开销,但它可以提高较大数据集的性能。
这一步对于真正的分布式环境至关重要。
重新运行带有 retrieve_task 函数的示例,以确认它按预期执行。
非阻塞调用#
在上一节中,您使用了 ray.get(object_references) 来检索结果。
此调用会阻止驱动程序进程,直到所有结果都可用为止。
如果每个数据库项都需要几分钟才能处理,则这种依赖关系可能会导致问题。
如果您允许驱动程序进程在等待结果时执行其他任务,并在结果完成时处理结果而不是等待所有项完成,则可以提高效率。
此外,如果由于数据库连接死锁等问题而无法检索某个数据库项,则驱动程序将无限期挂起。
为防止无限期挂起, 在使用 wait 函数时设置合理的 timeout 值。
例如,如果您希望等待的时间少于最慢数据检索任务时间的十倍,
请使用 wait 函数在该时间过后停止该任务。
start = time.time()
object_references = [
retrieve_task.remote(item, db_object_ref) for item in range(8)
]
all_data = []
while len(object_references) > 0:
finished, object_references = ray.wait(
object_references, timeout=7.0
)
data = ray.get(finished)
print_runtime(data, start)
all_data.extend(data)
print_runtime(all_data, start)
Runtime: 0.11 seconds, data:
(0, 'Learning')
(1, 'Ray')
Runtime: 0.31 seconds, data:
(2, 'Flexible')
(3, 'Distributed')
Runtime: 0.51 seconds, data:
(4, 'Python')
(5, 'for')
Runtime: 0.71 seconds, data:
(6, 'Machine')
(7, 'Learning')
Runtime: 0.71 seconds, data:
(0, 'Learning')
(1, 'Ray')
(2, 'Flexible')
(3, 'Distributed')
(4, 'Python')
(5, 'for')
(6, 'Machine')
(7, 'Learning')
不用打印结果,而是可以使用 while 循环内检索到的值来启动其他工作 worker 的新任务。
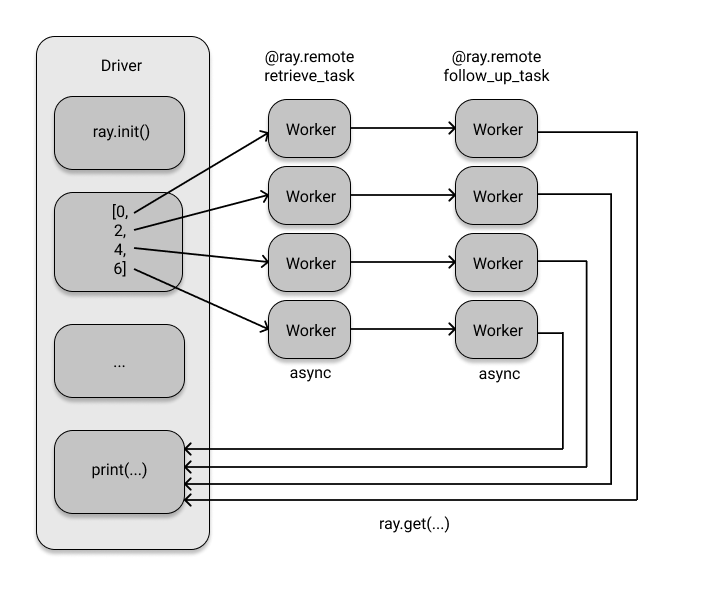
任务依赖#
您可能希望对检索到的数据执行额外的处理任务。例如,
使用第一个检索任务的结果从同一数据库(可能来自不同的表)查询其他相关数据。
下面的代码设置了此任务的后续任务 retrieve_task 和 follow_up_task 按顺序执行。
@ray.remote
def follow_up_task(retrieve_result):
original_item, _ = retrieve_result
follow_up_result = retrieve(original_item + 1)
return retrieve_result, follow_up_result
retrieve_refs = [retrieve_task.remote(item, db_object_ref) for item in [0, 2, 4, 6]]
follow_up_refs = [follow_up_task.remote(ref) for ref in retrieve_refs]
result = [print(data) for data in ray.get(follow_up_refs)]
((0, 'Learning'), (1, 'Ray'))
((2, 'Flexible'), (3, 'Distributed'))
((4, 'Python'), (5, 'for'))
((6, 'Machine'), (7, 'Learning'))
如果您不熟悉异步编程,这个示例可能并不特别令人印象深刻。 但是,再看一眼,您可能会惊讶于代码居然可以运行。 该代码似乎是一个带有一些列表推导的常规 Python 函数。
follow_up_task 函数体需要 Python 元组作为其输入参数 retrieve_result。
但是,当您使用 [follow_up_task.remote(ref) for ref in retrieve_refs] 命令时,
您不会将元组传递给后续任务。
相反,您使用 retrieve_refs 传入 Ray 对象引用。
在后台, Ray 识别 follow_up_task 需要的实际值,
因此它未来 自动 使用 ray.get 函数来解决问题。
此外,Ray 为所有任务创建依赖关系图,并以尊重其依赖关系的方式执行它们。
您不必明确告诉 Ray 何时等待上一个任务完成 - 它会推断出执行顺序。
Ray 对象存储的这一功能非常有用,因为您可以通过将对象引用传递给下一个任务
并让 Ray 处理其余部分来避免将较大的中间值复制回驱动程序。
只有在专门设计用于检索信息的任务完成后,才会安排流程中的后续步骤。
事实上,如果 retrieve_refs 调用了 retrieve_result,您可能没有注意到这个至关重要且有意命名的细微差别。Ray 让您专注于工作,而不是集群计算的技术细节。
这两个任务的依赖关系图如下所示:
Ray Actors#
此示例涵盖了 Ray Core 的另一个重要方面。
在此步骤之前,所有内容本质上都是函数。
使用 @ray.remote 装饰器使某些函数远程化,但除此之外,您只使用了标准 Python。
如果您想跟踪查询数据库的频率,可以计算检索任务的结果。 但是,有没有更有效的方法呢?理想情况下,您希望以分布式方式跟踪此情况,以便处理大量数据。 Ray 提供了一种带有 actor 的解决方案,这些 actor 在集群上运行有状态计算,还可以相互通信。 与使用修饰函数创建 Ray 任务的方式类似,使用修饰 Python 类创建 Ray actor。 因此,您可以使用 Ray actor 创建一个简单的计数器来跟踪数据库调用的次数。
@ray.remote
class DataTracker:
def __init__(self):
self._counts = 0
def increment(self):
self._counts += 1
def counts(self):
return self._counts
当您为 DataTracker 类赋予装饰器 ray.remote 时,该类将成为 actor。 此 actor 能够跟踪状态
(例如计数),其方法是 Ray actor 任务,您可以像使用 .remote() 函数一样来调用它。
修改 withdraw_task 以合并此 actor。
@ray.remote
def retrieve_tracker_task(item, tracker, db):
time.sleep(item / 10.)
tracker.increment.remote()
return item, db[item]
tracker = DataTracker.remote()
object_references = [
retrieve_tracker_task.remote(item, tracker, db_object_ref) for item in range(8)
]
data = ray.get(object_references)
print(data)
print(ray.get(tracker.counts.remote()))
[(0, 'Learning'), (1, 'Ray'), (2, 'Flexible'), (3, 'Distributed'), (4, 'Python'), (5, 'for'), (6, 'Machine'), (7, 'Learning')]
8
正如预期的那样,此计算的结果为 8。 虽然您不需要 actor 来执行此计算,但这演示了一种在集群中维护状态的方法,可能涉及多个任务。 事实上,您可以将 actor 传递到任何相关任务中,甚至可以传递到不同 actor 的构造函数中。 Ray API 非常灵活,允许无限的可能性。 分布式 Python 工具很少允许有状态计算,这对于运行强化学习等复杂的分布式算法特别有用。
概括#
在此示例中,您仅使用了六种 API 方法
包括 ray.init() 启动集群、 @ray.remote 将函数和类转换为task 和 actor、
ray.put() 将值传输到 Ray 的对象存储中以及 ray.get() 从集群中检索对象。
此外,您还在 actor 方法或者任务上使用了 .remote() 在集群上执行代码,以及 ray.wait 防止阻塞调用。
Ray API 包含不止这六个调用,但如果您刚刚开始使用,这六个调用非常强大。 概括起来,这些方法如下:
ray.init(): 初始化您的 Ray 集群。传入一个地址以连接到现有集群。@ray.remote: 将函数转化为任务,将类转化为 actor 。ray.put(): 将值放入 Ray 的对象存储中。ray.get(): 从对象存储中获取值。返回您放在那里的值或由task 或 actor计算的值。.remote(): 在你的 Ray 集群上运行 actor 方法或任务,并用于实例化 actor 。ray.wait(): 返回两个对象引用列表,一个包含我们正在等待的已完成任务,另一个包含未完成的任务。
想要了解更多?#
此示例是我们 “Learning Ray”一书 中 Ray Core 演练的简化版本。 如果您喜欢它,请查看 Ray Core 示例库 或者我们 用例库 中的一些 ML 工作负载。