模型 Endpoints 测试¶
为了测试组件,可使用 CURL/grpCURL 或者相似工具,或者我们的 Python SeldonClient SDK。
Testing 选项¶
在部署模型之前,有几个选项用于测试模型。
直接用 Python 客户端运行模型
以 Docker 容器方式运行模型
此法可用于所有封装语言(除却预封装推理服务)
在 K8s 开发环境运行 SeldonDeployment,比如 KIND,或者 minikube
此法可用于所有模型
可通过生成的文档 UI, Python 客户端或者 CLI 工具发送请求
直接用 Python 客户端运行您的模型¶
只能用于使用 Python 封装语言的模型
创建带有逻辑的 Python 模型文件 MyModel.py:
class MyModel:
def __init__(self):
pass
def predict(*args, **kwargs):
return ["hello", "world"]
您可以通过运行 Python 模块提供的微服务 CLI 来测试您的模型 Python 模块
安装 Python seldon-core 模块后,可通过命令运行:
> seldon-core-microservice MyModel REST --service-type MODEL
2020-03-23 16:59:17,320 - seldon_core.microservice:main:190 - INFO: Starting microservice.py:main
2020-03-23 16:59:17,322 - seldon_core.microservice:main:246 - INFO: Parse JAEGER_EXTRA_TAGS []
2020-03-23 16:59:17,322 - seldon_core.microservice:main:257 - INFO: Annotations: {}
2020-03-23 16:59:17,322 - seldon_core.microservice:main:261 - INFO: Importing Model
hello world
2020-03-23 16:59:17,323 - seldon_core.microservice:main:325 - INFO: REST microservice running on port 5000
2020-03-23 16:59:17,323 - seldon_core.microservice:main:369 - INFO: Starting servers
* Serving Flask app "seldon_core.wrapper" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
2020-03-23 16:59:17,366 - werkzeug:_log:122 - INFO: * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
现在,我们的模型微服务正在运行,我们可以使用 curl 发送请求:
> curl -X POST \
> -H 'Content-Type: application/json' \
> -d '{"data": { "ndarray": [[1,2,3,4]]}}' \
> http://localhost:5000/api/v1.0/predictions
{"data":{"names":[],"ndarray":["hello","world"]},"meta":{}}
我们可以看到模型通过 API 返回的输出。
您也可以使用 Python 客户端 发送请求。
以 Docker 容器方式运行模型¶
如果以其他封装语言创建模型,可在本地 Docker 客户端运行 S2I 构建的模型。
为此,您只需使用以下命令运行 Docker 客户端:
docker run --rm --name mymodel -p 5000:5000 mymodel:0.1
模型将运行在端口 5000 上,因此我们可以使用 CURL 发送请求:
> curl -X POST \
> -H 'Content-Type: application/json' \
> -d '{"data": { "ndarray": [[1,2,3,4]]}}' \
> http://localhost:5000/api/v1.0/predictions
{"data":{"names":[],"ndarray":["hello","world"]},"meta":{}}
您也可以使用 Python 客户端 发送请求。
在K8s中测试模型¶
对于 Kubernetes,您可以按照文档的安装部分设置一个集群。
您也可以使用本地客户端(如 KIND,我们使用 Kind 开发并进行 e2e 测试)来运行 Seldon。
一旦通过 Kind 或自建 k8s 集群完成,你需要为集群创建 Ingress (如安装文档中所述) 支持,只会,可以向模型发送请求。
根据你 Seldon Core 设定的 Ambassador 或 API 网关,可以通过以下讨论方式访问模型:
生成的 Swagger UI¶
每个部署在 K8s 集群后的模型都会暴露标准化的用户界面,以便使用我们的 OpenAPI 模式发送请求。
通过浏览器访问 http://<ingress_url>/seldon/<namespace>/<model-name>/api/v1.0/doc/ 节点来发送请求。
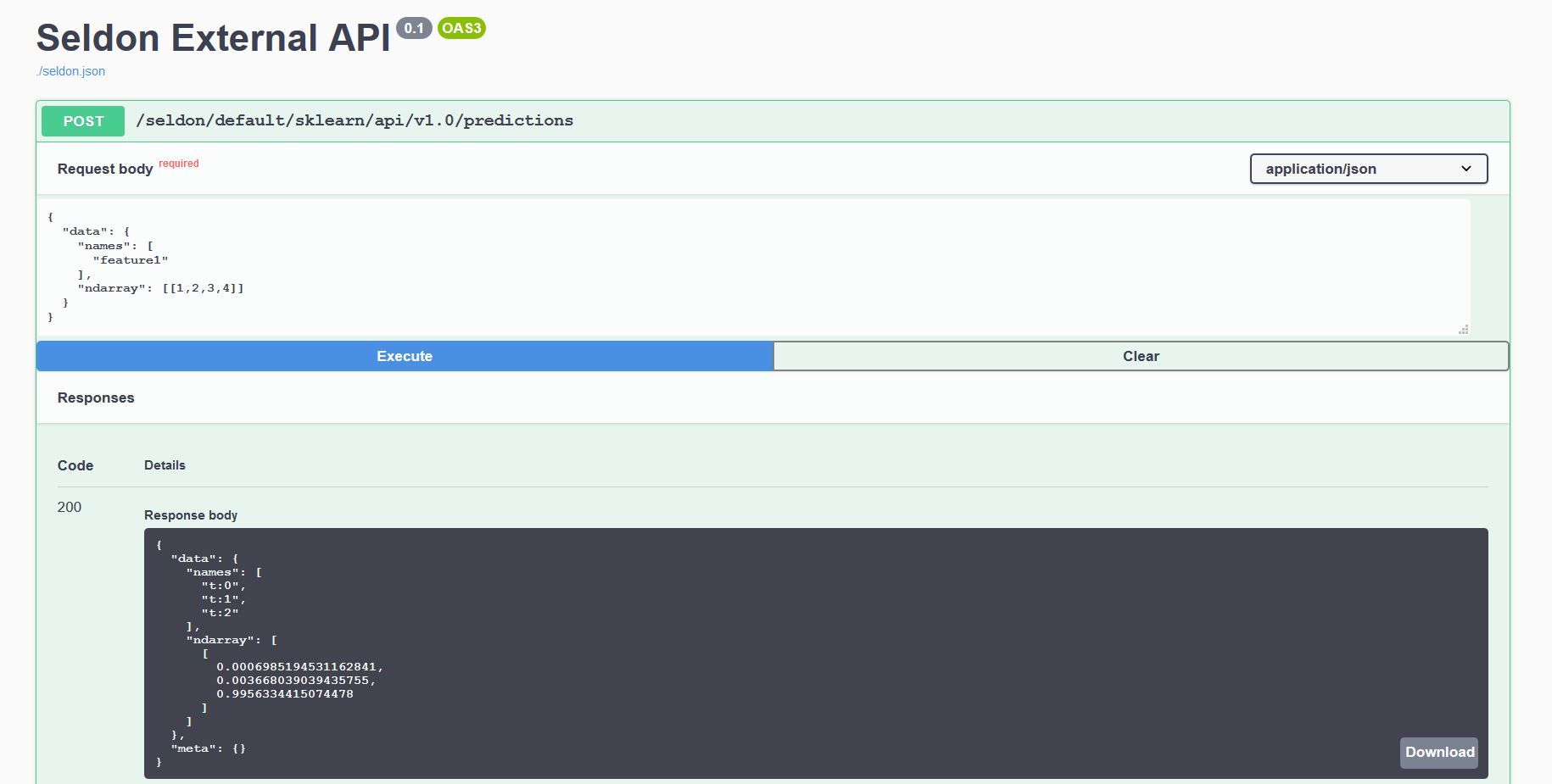
Ambassador¶
Ambassador REST¶
假设名为 <deploymentName> 的 Seldon deployment 在命名空间 <namespace> 通过 Ambassador 中暴露在 <ambassadorEndpoint> 节点:
REST节点暴露为 :
http://<ambassadorEndpoint>/seldon/<namespace>/<deploymentName>/api/v1.0/predictions
Ambassador gRPC¶
假设名为 <deploymentName> 的 Seldon deployment 通过 Ambassador 暴露在 <ambassadorEndpoint>:
gRPC 节点暴露为
<ambassadorEndpoint>,你需要在请求中设置 metadata 头信息seldon参数和<deploymentName>值namespace参数和<namespace>值
Istio¶
Istio REST¶
假设名为 <deploymentName> 的 Seldon deployment,通过命名空间 <namespace> 通过暴露在 istio 网关 <istioGateway>:
REST 节点暴露为:
http://<istioGateway>/seldon/<namespace>/<deploymentName>/api/v1.0/predictions
Istio gRPC¶
假设名为 <deploymentName> 的 Seldon deployment 在命名空间 <namespace> 通过 istio 网关 <istioGateway> 暴露:
gRPC 节点暴露为
<istioGateway>,你需要在请求中设置 metadata 头信息seldon参数和<deploymentName>值namespace参数和<namespace>值
客户端实现¶
Curl 示例¶
Ambassador REST¶
假设 SeldonDeployment mymodel 通过 Ambassador 暴露 0.0.0.0:8003:
curl -v 0.0.0.0:8003/seldon/mymodel/api/v1.0/predictions -d '{"data":{"names":["a","b"],"tensor":{"shape":[2,2],"values":[0,0,1,1]}}}' -H "Content-Type: application/json"
OpenAPI REST¶
使用 Swagger 信息请参考 OpenAPI 定义.
gRPC¶
使用 gRPC 工具在你所选的语言中,请参考 proto buffer 定义
PYTHON 客户端参考¶
使用我们的 python 客户端参考,他是 seldon-core 模块的一部分。